
Meta hat das Open-Source-Modell Llama 3 veröffentlicht, das vortrainierte und auf Befehle abgestimmte Modelle mit 8B und 70B Parametern sowie eine neue Version seines KI-Assistenten enthält.
Die Vollversion von Llama3 wird voraussichtlich im Juli dieses Jahres verfügbar sein und über multimodale Funktionen verfügen. Meta hat in Llama3 neue Funktionen für die Computercodierung eingebettet, die Text und Bilder ausgeben und auf die intelligente Brille Ray-Ban Meta angewendet werden sollen. Meta ist eine Partnerschaft mit Google eingegangen, um Echtzeit-Suchergebnisse in die Antworten des KI-Assistenten zu integrieren.
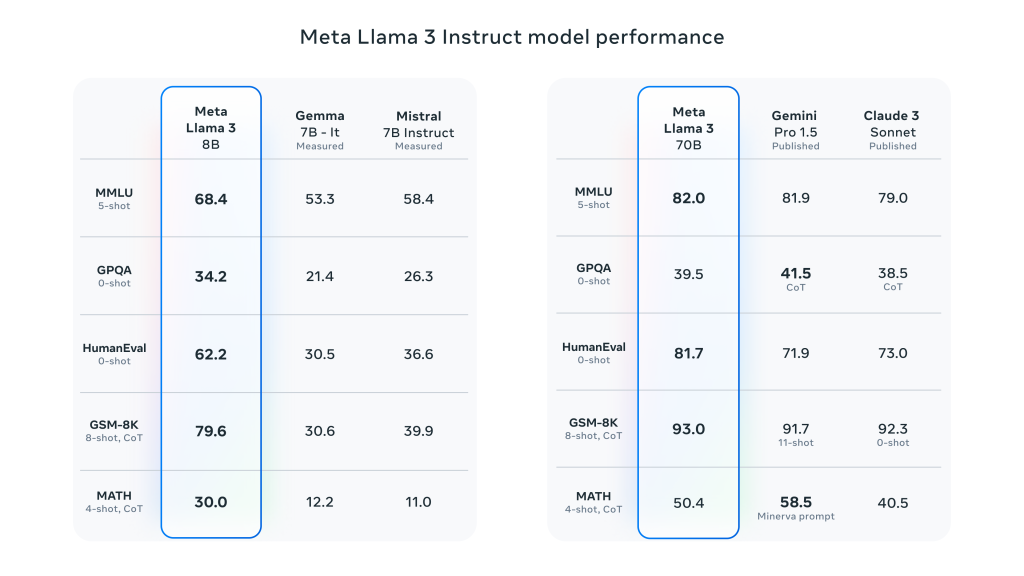
Llama 3 macht einen großen Sprung nach vorn gegenüber Llama 2 und demonstriert die SOTA-Leistung bei einer Vielzahl von Industrie-Benchmarks. Zusätzlich zur verbesserten Inferenz, Codegenerierung und Befehlsverfolgung reduzieren diese Modelle die Falschrückweisungsraten erheblich, verbessern die Ausrichtung und erhöhen die Vielfalt der Modellantworten. Meta erstellte zu diesem Zweck zwei 24.000-GPU-Cluster und ließ die Llama 3-Modelle auf 16.000 dieser GPUs gleichzeitig trainieren!
Meta behauptet, dass die Llama 3 8B und 70B Modelle nur der Anfang der Bemühungen für die offizielle Llama 3 Veröffentlichung sind. Die Das größte Modell, an dem derzeit gearbeitet wird, ist der Parameter 400B+.Sie befinden sich zwar noch in der Entwicklungsphase, sind aber sehr gespannt auf die weitere Entwicklung dieser Arbeit.
Die wichtigsten Leistungsmerkmale von Meta Llama 3 im Detail:
- Modellgrößen und -typen:
- Größe der Parameter: Meta Llama 3 bietet Modelle in den Größen 8B (8 Milliarden) und 70B (70 Milliarden).
- Modell TypDiese Modelle sind vortrainierte und auf Anweisungen abgestimmte generative Textmodelle, die für den Einsatz in Gesprächen und anderen Sprachverarbeitungsaufgaben optimiert sind.
- Modell der Architektur:
- Autoregressives Sprachmodell: Llama 3 verwendet einen autoregressiven Ansatz zur Texterstellung, der auf einer optimierten Transformer-Architektur basiert.
- Aufmerksamkeit bei Gruppenabfragen (GQA): Der Aufmerksamkeitsmechanismus für gruppierte Abfragen wird in dem Modell verwendet, um die Skalierbarkeit der Schlussfolgerungen bei großen Parametern zu verbessern.
- Ausbildung und Datenverarbeitung:
- Menge der Trainingsdaten: Llama 3 verwendet über 15 Billionen Token für das Vortraining, mit einer siebenmal größeren Trainingsmenge als Llama 2, einschließlich der vierfachen Menge an Code.
- Feinkörnige AbstimmungDas Modell wird mittels überwachter Feinabstimmung (SFT) und Verstärkungslernen mit menschlichem Feedback (RLHF) auf die Anweisungen abgestimmt, um den menschlichen Präferenzen für Nützlichkeit und Sicherheit besser zu entsprechen.
- Der Pre-Training-Datensatz hat 5% nicht-englischer Datensatzmit einer Gesamtzahl von bis zu 30 unterstützt Sprachen
- Leistung und Benchmarking:
- Allgemeine Leistungsverbesserung: Llama 3 schneidet in mehreren automatisierten Benchmarks bei einer Vielzahl von Aufgaben gut ab, darunter Dialoge, Fragen und Antworten und logisches Denken.
- Benchmark-Vergleich: Im Vergleich zu früheren Modellen (z. B. Llama 2) zeigt Llama 3 deutliche Leistungssteigerungen bei mehreren Aufgaben.









Schreibe einen Kommentar