
Meta ha lanzado el modelo de código abierto Llama 3, que incluye modelos preentrenados y ajustados a comandos con parámetros 8B y 70B, así como una nueva versión de su asistente de IA.
Se espera que la versión completa de Llama3 esté disponible en julio, con capacidades multimodales. Meta ha incorporado a Llama3 nuevas capacidades de codificación informática, con salida de texto e imágenes, que planea aplicar a las gafas inteligentes Ray-Ban Meta. Meta se ha asociado con Google para incluir resultados de búsqueda en tiempo real en las respuestas del asistente de inteligencia artificial.
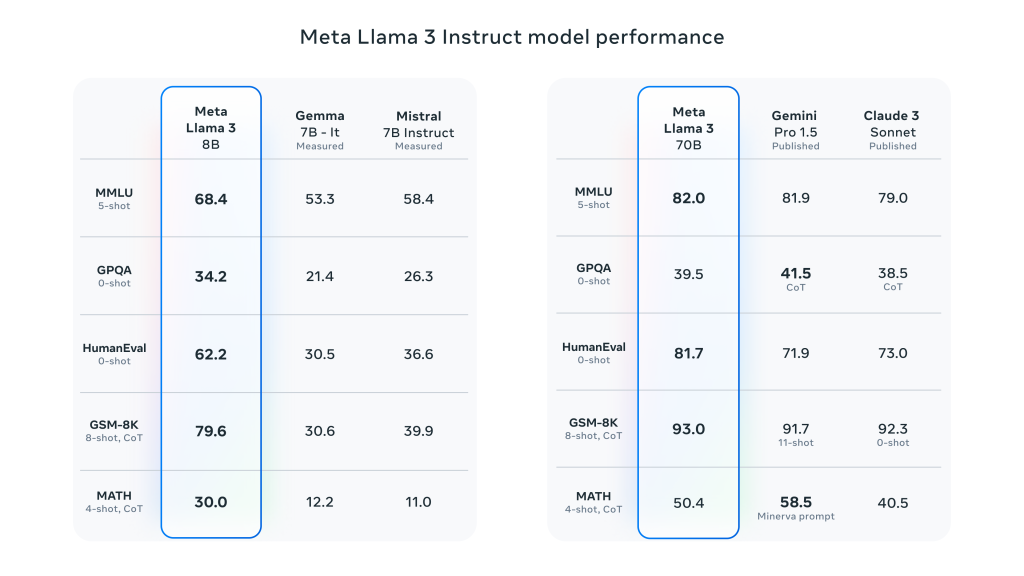
Llama 3 supone un gran avance con respecto a Llama 2 y demuestra el rendimiento SOTA en una amplia gama de pruebas de referencia del sector. Además de mejorar la inferencia, la generación de código y el seguimiento de instrucciones, estos modelos reducen significativamente las tasas de falsos rechazos, mejoran la alineación y aumentan la diversidad de las respuestas del modelo. Para ello, Meta creó dos clusters de 24.000 GPU y entrenó los modelos de Llama 3 en 16.000 de estas GPU simultáneamente.
Meta afirma que los modelos Llama 3 8B y 70B son sólo el principio del esfuerzo para el lanzamiento oficial de Llama 3. El sitio modelo más grande en el que trabajan actualmente es el parámetro 400B+.y, aunque todavía están en fase de desarrollo activo, están muy entusiasmados con el rumbo que está tomando este trabajo.
Características clave detalladas de Meta Llama 3:
- Tamaños y tipos de modelos:
- Tamaño de los parámetros: Meta Llama 3 ofrece modelos de tamaño 8B (8.000 millones) y 70B (70.000 millones).
- Tipo de modeloEstos modelos son modelos generativos de texto preentrenados y ajustados a las instrucciones, optimizados para su uso en conversaciones y otras tareas de procesamiento del lenguaje.
- Arquitectura modelo:
- Modelo autorregresivo del lenguaje: Llama 3 utiliza un enfoque autorregresivo para generar texto, basado en una arquitectura Transformer optimizada.
- Atención a consultas agrupadas (GQA): El mecanismo Grouped-Query Attention se utiliza en el modelo para mejorar la escalabilidad de la inferencia bajo parámetros a gran escala.
- Formación y tratamiento de datos:
- Volumen de datos de formación: Llama 3 utiliza más de 15 billones fichas para el preentrenamiento, con un conjunto de entrenamiento siete veces mayor que Llama 2, que incluye cuatro veces más código.
- Ajuste precisoel modelo se ajusta a las instrucciones mediante el ajuste fino supervisado (SFT) y el aprendizaje por refuerzo que incorpora la retroalimentación humana (RLHF) para ajustarse mejor a las preferencias humanas de utilidad y seguridad.
- El conjunto de datos de preentrenamiento tiene 5% conjunto de datos no en ingléscon un total de hasta un 30 compatible idiomas
- Rendimiento y evaluación comparativa:
- Mejora general del rendimiento: Llama 3 obtiene buenos resultados en varias pruebas comparativas automatizadas en una amplia gama de tareas, como el diálogo, las preguntas y respuestas y el razonamiento.
- Comparación: En comparación con los modelos anteriores (por ejemplo, Llama 2), Llama 3 muestra mejoras significativas de rendimiento en múltiples tareas.









Deja una respuesta