
Meta a publié le modèle open-source Llama 3, qui comprend des modèles pré-entraînés et adaptés aux commandes avec 8B et 70B paramètres, ainsi qu'une nouvelle version de son assistant d'intelligence artificielle.
La version complète de Llama3 devrait être disponible en juillet, avec des capacités multimodales. Meta a intégré de nouvelles capacités de codage informatique dans Llama3, produisant du texte et des images, qu'elle prévoit d'appliquer aux lunettes intelligentes Ray-Ban Meta. Meta a conclu un partenariat avec Google pour inclure des résultats de recherche en temps réel dans les réponses de l'assistant d'intelligence artificielle.
Llama 3 fait un grand pas en avant par rapport à Llama 2 et démontre des performances SOTA sur une large gamme de références industrielles. Outre l'amélioration de l'inférence, de la génération de code et du suivi des instructions, ces modèles réduisent considérablement les taux de faux rejets, améliorent l'alignement et augmentent la diversité des réponses du modèle. Meta a créé deux grappes de 24 000 GPU à cette fin et a entraîné les modèles Llama 3 sur 16 000 de ces GPU simultanément !
Meta affirme que les modèles Llama 3 8B et 70B ne sont que le début de l'effort pour la sortie officielle de la Llama 3. Les le plus grand modèle sur lequel ils travaillent actuellement est le paramètre 400B+.et, bien qu'ils soient encore en cours de développement, ils sont très enthousiastes quant à l'orientation de ces travaux.
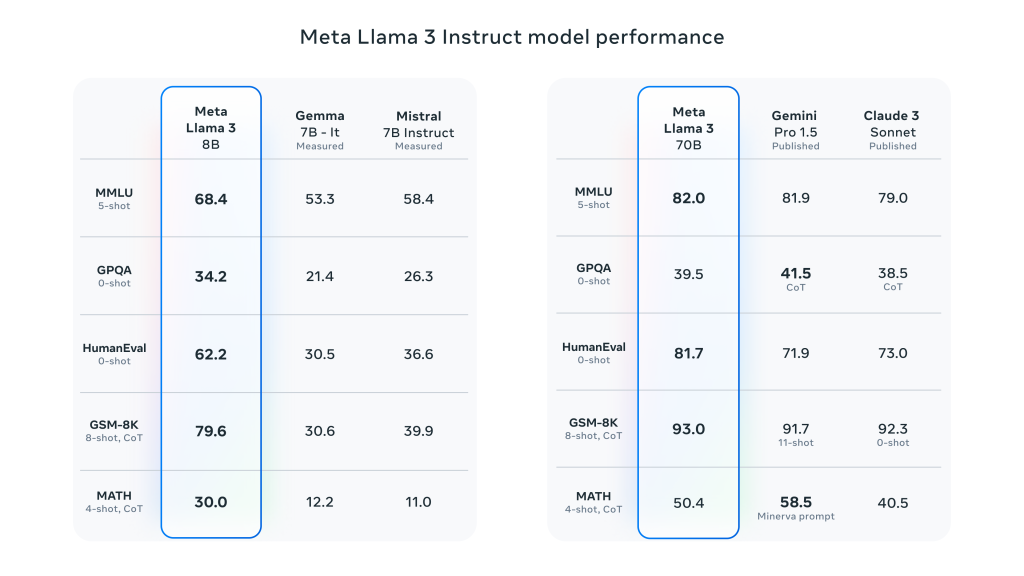
Caractéristiques détaillées des performances du Meta Llama 3:
- Tailles et types de modèles:
- Taille des paramètres: Meta Llama 3 fournit des modèles de taille 8B (8 milliards) et 70B (70 milliards).
- Type de modèleCes modèles sont des modèles de texte génératifs pré-entraînés et adaptés aux instructions, optimisés pour être utilisés dans des conversations et d'autres tâches de traitement du langage.
- Modèle d'architecture:
- Modèle linguistique autorégressif: Llama 3 utilise une approche autorégressive pour générer du texte, basée sur une architecture Transformer optimisée.
- Attention à la recherche groupée (GQA): Le mécanisme d'attention par requête groupée est utilisé dans le modèle pour améliorer l'évolutivité de l'inférence en présence de paramètres à grande échelle.
- Formation et traitement des données:
- Volume des données d'apprentissage: Le lama 3 utilise plus de 15 billions jetons pour le pré-entraînement, avec un ensemble d'entraînement sept fois plus grand que Llama 2, comprenant quatre fois plus de code.
- Un réglage précisLe modèle est adapté aux instructions par le biais d'un réglage fin supervisé (SFT) et d'un apprentissage par renforcement intégrant un retour d'information humain (RLHF) afin de mieux correspondre aux préférences humaines en matière d'utilité et de sécurité.
- L'ensemble de données de pré-entraînement est composé de 5% ensemble de données non anglaises, avec un total de jusqu'à 30 soutenu langues
- Performances et étalonnage des performances:
- Amélioration des performances globales: Llama 3 obtient de bons résultats dans plusieurs tests automatisés sur un large éventail de tâches, y compris le dialogue, les questions-réponses et le raisonnement.
- Comparaison des points de repère: Comparé aux modèles précédents (par exemple, le Llama 2), le Llama 3 présente des gains de performance significatifs dans de multiples tâches.









Laisser un commentaire