
メタ社は、8Bと70Bのパラメータで事前に訓練され、コマンドチューニングされたモデルを含むオープンソースモデルLlama 3と、AIアシスタントの新バージョンをリリースした。
Llama3のフルバージョンは、マルチモーダル機能を備え、今年7月に発売される予定だ。メタ社は、Llama3に新しいコンピューター・コーディング機能を組み込み、テキストや画像を出力する。メタはグーグルと提携し、AIアシスタントの応答にリアルタイムの検索結果を含める。
Llama 3はLlama 2から大きく飛躍し、広範な業界ベンチマークでSOTA性能を実証しています。推論、コード生成、命令追跡が改善されたことに加え、これらのモデルは誤判定率を大幅に低減し、アライメントを改善し、モデル応答の多様性を高めています。Meta社は、この目的のために2つの24,000 GPUクラスターを作成し、Llama 3モデルをこれらのGPUのうち16,000GPUで同時に学習させました!
メタ社は、ラマ3 8Bと70Bのモデルはラマ3の正式リリースに向けた努力の始まりに過ぎないと主張している。その 彼らが現在取り組んでいる最大のモデルは400B+パラメータである。まだ積極的に開発中ではあるが、彼らはこの仕事の方向性にとても興奮している。
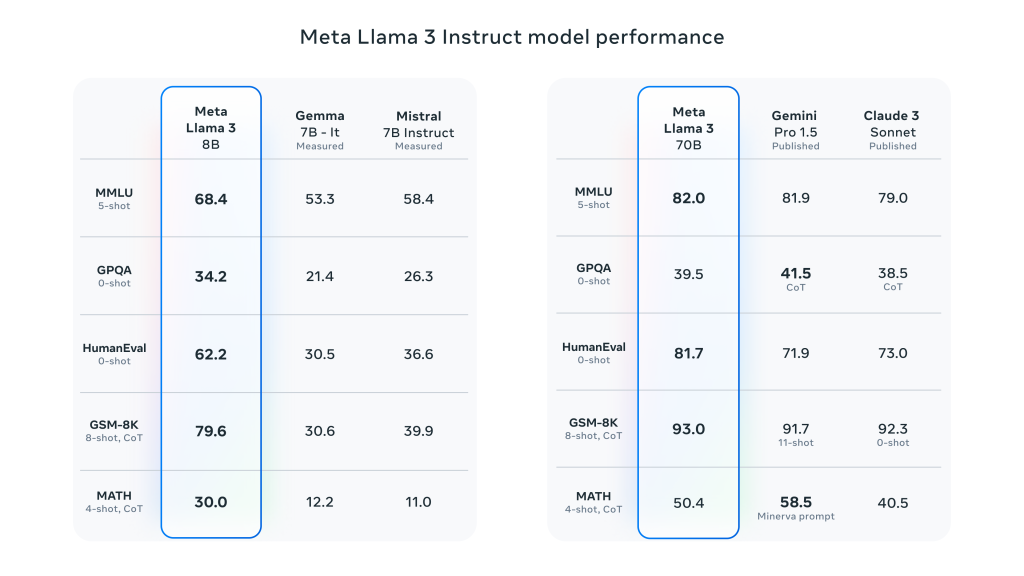
Meta Llama 3の主要性能詳細:
- モデルのサイズとタイプ:
- パラメータ・サイズ:Meta Llama 3には、8B(80億)と700B(700億)の両方のサイズがあります。
- モデルタイプこれらのモデルは、会話や他の言語処理タスクで使用するために最適化された、事前にトレーニングされ、インストラクションチューニングされた生成テキストモデルです。
- モデル建築:
- 自己回帰言語モデル:Llama 3は、最適化されたTransformerアーキテクチャに基づいて、テキストを生成するために自己回帰的アプローチを使用しています。
- グループ化クエリー・アテンション(GQA):Grouped-Query Attentionメカニズムにより、大規模なパラメータに対する推論のスケーラビリティを向上。
- トレーニングとデータ処理:
- トレーニングデータ量:ラマ3は15兆回以上使用 トークン 事前学習には、Llama 2の7倍の学習セットと4倍のコード量を使用した。
- きめ細かなチューニングこのモデルは、教師あり微調整(SFT)と、人間のフィードバックを取り入れた強化学習(RLHF)を通じて、有用性と安全性に対する人間の嗜好によりマッチするように、命令のチューニングが行われる。
- 事前学習データセットには 5%非英語データセット合計で 最大30 対応 言語
- パフォーマンスとベンチマーク:
- 全体的なパフォーマンス向上:Llama 3は、対話、Q&A、推論を含む幅広いタスクにおいて、いくつかの自動化ベンチマークで良好な結果を示した。
- ベンチマーク比較:以前のモデル(例:ラマ2)と比べて、ラマ3は複数のタスクで大幅なパフォーマンス向上を示している。









コメントを残す