
Meta has released the open-source model Llama 3, including pre-trained and command-tuned models with 8B and 70B parameters, as well as a new version of its AI assistant.
The full version of Llama3 is expected to be available this July, with multimodal capabilities. Meta has embedded new computer coding capabilities into Llama3, outputting text and images, which it plans to apply to Ray-Ban Meta smart glasses. Meta has partnered with Google to include real-time search results in the AI assistant’s responses.
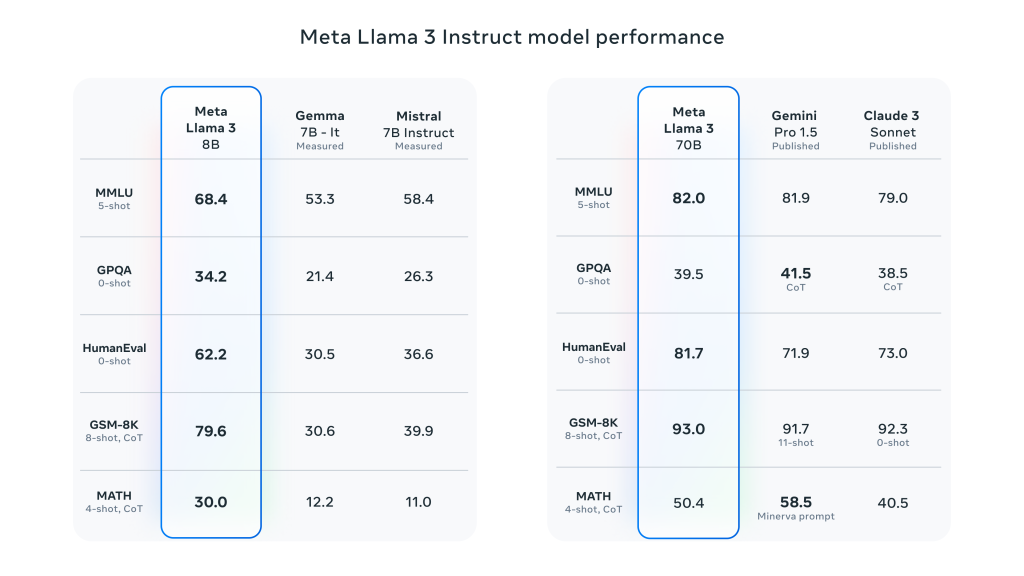
Llama 3 takes a major leap forward from Llama 2 and demonstrates SOTA performance on a wide range of industry benchmarks. In addition to improved inference, code generation, and instruction tracking, these models significantly reduce false reject rates, improve alignment, and increase the diversity of model responses. Meta created two 24,000 GPU clusters for this purpose, and had the Llama 3 models trained on 16,000 of these GPUs simultaneously!
Meta claims that the Llama 3 8B and 70B models are just the beginning of the effort for the official Llama 3 release. The largest model they are currently working on is the 400B+ parameter, and while they are still under active development, they are very excited about where this work is headed.
Detailed key performance characteristics of Meta Llama 3:
- Model sizes and types:
- Parameter size: Meta Llama 3 provides models of both 8B (8 billion) and 70B (70 billion) sizes.
- Model type: these models are pre-trained and instruction-tuned generative text models optimized for use in conversations and other language processing tasks.
- Model Architecture:
- Autoregressive Language Model: Llama 3 uses an autoregressive approach to generate text, based on an optimized Transformer architecture.
- Grouped-Query Attention (GQA): The Grouped-Query Attention mechanism is used in the model to improve inference scalability under large-scale parameters.
- Training and Data Processing:
- Volume of training data: Llama 3 uses over 15 trillion tokens for pre-training, with a training set seven times larger than Llama 2, including four times the amount of code.
- Fine-grained tuning: the model is tuned for instructions via supervised fine-tuning (SFT) and reinforcement learning incorporating human feedback (RLHF) to better match human preferences for usefulness and safety.
- The pre-training dataset has 5% non-English dataset, with a total of up to 30 supported languages
- Performance and Benchmarking:
- Overall Performance Improvement: Llama 3 performs well in several automated benchmarks on a wide range of tasks, including dialog, Q&A, and reasoning.
- Benchmark Comparison: Compared to previous models (e.g., Llama 2), Llama 3 shows significant performance gains across multiple tasks.




Leave a Reply