
A Meta lançou o modelo de código aberto Llama 3, incluindo modelos pré-treinados e ajustados por comando com parâmetros 8B e 70B, bem como uma nova versão do seu assistente de IA.
Prevê-se que a versão completa do Llama3 esteja disponível em julho, com capacidades multimodais. A Meta incorporou novas capacidades de codificação informática no Llama3, produzindo texto e imagens, que planeia aplicar aos óculos inteligentes Ray-Ban Meta. A Meta estabeleceu uma parceria com a Google para incluir resultados de pesquisa em tempo real nas respostas do assistente de IA.
A Llama 3 dá um grande salto em relação à Llama 2 e demonstra um desempenho SOTA numa vasta gama de referências da indústria. Para além da inferência melhorada, da geração de código e do seguimento de instruções, estes modelos reduzem significativamente as taxas de falsas rejeições, melhoram o alinhamento e aumentam a diversidade das respostas do modelo. A Meta criou dois clusters de 24.000 GPUs para este efeito e treinou os modelos Llama 3 em 16.000 destas GPUs em simultâneo!
A Meta afirma que os modelos Llama 3 8B e 70B são apenas o início do esforço para o lançamento oficial da Llama 3. A O maior modelo em que estão atualmente a trabalhar é o parâmetro 400B+e, embora ainda estejam em desenvolvimento ativo, estão muito entusiasmados com o rumo que este trabalho está a tomar.
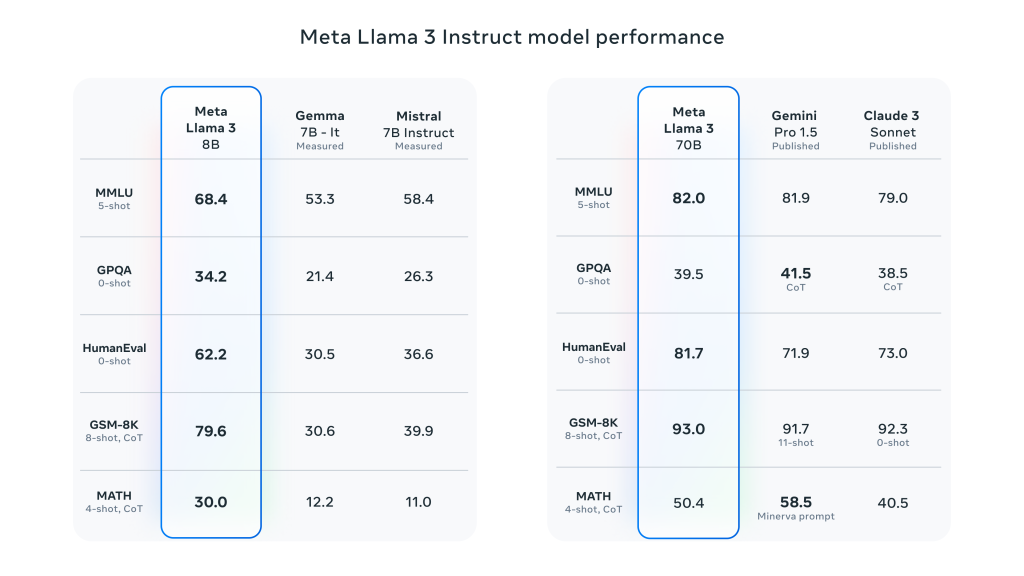
Caraterísticas pormenorizadas dos principais desempenhos da Meta Llama 3:
- Tamanhos e tipos de modelos:
- Tamanho do parâmetro: O Meta Llama 3 fornece modelos de 8B (8 mil milhões) e 70B (70 mil milhões).
- Tipo de modelo: estes modelos são modelos de texto generativos pré-treinados e ajustados por instruções, optimizados para utilização em conversações e outras tarefas de processamento de linguagem.
- Arquitetura de modelos:
- Modelo linguístico autoregressivo: O Llama 3 utiliza uma abordagem autoregressiva para gerar texto, com base numa arquitetura optimizada do Transformer.
- Atenção de consulta agrupada (GQA): O mecanismo de atenção por consulta agrupada é utilizado no modelo para melhorar a escalabilidade da inferência com parâmetros de grande escala.
- Formação e tratamento de dados:
- Volume de dados de treino: Llama 3 utiliza mais de 15 biliões fichas para pré-treino, com um conjunto de treino sete vezes maior do que o Llama 2, incluindo quatro vezes a quantidade de código.
- Sintonia finaO modelo é ajustado para instruções através de um ajuste fino supervisionado (SFT) e de uma aprendizagem por reforço que incorpora o feedback humano (RLHF) para melhor corresponder às preferências humanas em termos de utilidade e segurança.
- O conjunto de dados de pré-treino tem 5% conjunto de dados não inglês, com um total de até 30 apoiado línguas
- Desempenho e avaliação comparativa:
- Melhoria do desempenho global: O Llama 3 tem um bom desempenho em vários testes de referência automatizados numa vasta gama de tarefas, incluindo diálogo, perguntas e respostas e raciocínio.
- Comparação de Benchmark: Em comparação com os modelos anteriores (por exemplo, Llama 2), Llama 3 apresenta ganhos de desempenho significativos em várias tarefas.









Deixe um comentário