
Meta 发布了开源模型 Llama 3,包括 8B 和 70B 参数的预训练和命令调整模型,以及新版人工智能助手。
Llama3 的完整版预计将于今年 7 月推出,并具备多模态功能。Meta 在 Llama3 中嵌入了新的计算机编码功能,可以输出文本和图像,并计划将其应用到雷朋 Meta 智能眼镜上。Meta 与谷歌合作,在人工智能助手的回复中加入实时搜索结果。
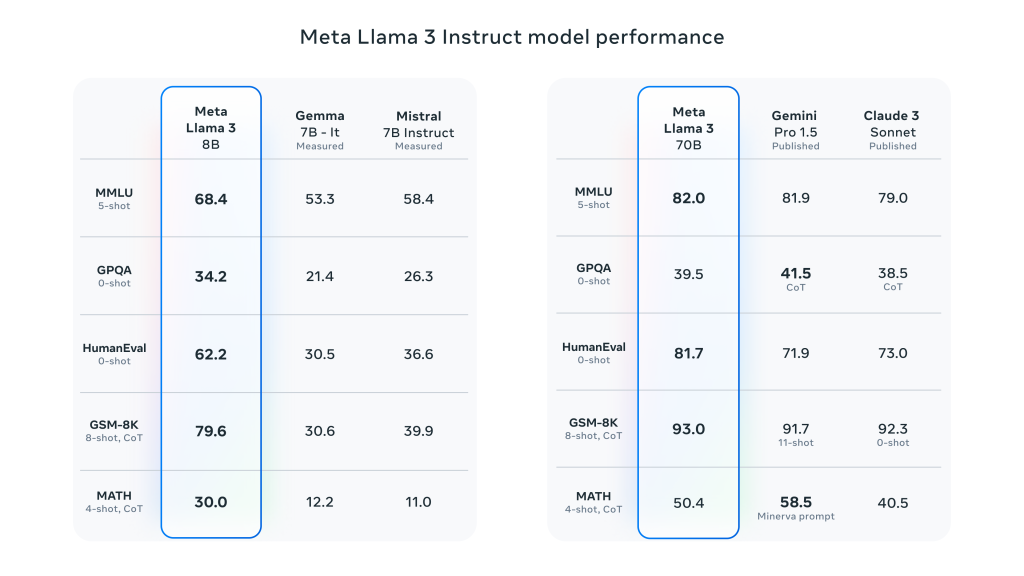
Llama 3 在 Llama 2 的基础上实现了重大飞跃,并在广泛的行业基准测试中展示了 SOTA 性能。除了改进推理、代码生成和指令跟踪外,这些模型还显著降低了错误拒绝率,提高了对齐度,并增加了模型响应的多样性。Meta 为此创建了两个 24,000 个 GPU 集群,并在其中 16,000 个 GPU 上同时训练 Llama 3 模型!
Meta 声称,Llama 3 8B 和 70B 型号只是正式发布 Llama 3 的开端。该系统 目前最大的型号是 400B+ 参数虽然它们仍在积极开发中,但他们对这项工作的发展方向感到非常兴奋。
Meta Llama 3 的详细主要性能特点:
- 机型尺寸和类型:
- 参数大小:Meta Llama 3 提供 8B(80 亿)和 70B(700 亿)两种大小的模型。
- 型号这些模型是经过预先训练和教学调整的生成文本模型,经过优化可用于对话和其他语言处理任务。
- 模型架构:
- 自回归语言模型:Llama 3 基于优化的 Transformer 架构,采用自回归方法生成文本。
- 分组查询注意力(GQA):模型中使用了分组查询关注机制,以提高大规模参数下的推理可扩展性。
- 培训和数据处理:
- 训练数据量:Llama 3 使用超过 15 万亿次 代币 进行预训练,其训练集比 Llama 2 大七倍,其中代码量是 Llama 2 的四倍。
- 微调模型:通过监督微调(SFT)和结合人类反馈的强化学习(RLHF)对指令进行调整,以更好地满足人类对有用性和安全性的偏好。
- 预训练数据集包括 5% 非英语数据集共计 高达 30 支持 语言
- 绩效与基准:
- 全面提高绩效:Llama 3 在对话、问答和推理等多项任务的自动基准测试中表现出色。
- 基准比较:与之前的模型(如 Llama 2)相比,Llama 3 在多项任务中的表现都有显著提高。









发表回复